
티스토리 뷰
rnn.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
https://blog.naver.com/demian7607/222043724449
구글 코랩(colab) GPU 딥러닝 케라스(keras) 돌리기[추가.CPU랑 속도 비교]
1. 데이터 세팅 (불러올 파일 경로 설정을 해줘야해요 : 드라이브 마운트 이용해야 함!) 보기 -> 목차 -...
blog.naver.com
코랩과 구글 드라이브 연동(파일 불러오기, 읽고, 쓰고, 저장하기)
1. 현재 위치 확인하기 구글 드라이브에서 코랩 노트북을 열고 코드 셀에 'pwd'를 입력한다. 실행 후 '/content'라는 경로에 있음을 확인할 수 있다. 빨간 동그라미 속 아이콘을 클릭하면 파일 탐색을
official-hacademi.tistory.com
하루 체온 변화의 리듬이 항상성을 가진다면 체온으로 시간을 예측할 수 있지 않을까

[1]
C. Harding, F. Pompei, S. F. Bordonaro, D. C. McGillicuddy, D. Burmistrov, and L. D. Sanchez, “The daily, weekly, and seasonal cycles of body temperature analyzed at large scale,” Chronobiology International, vol. 36, no. 12, pp. 1646–1657, Dec. 2019, doi: 10.1080/07420528.2019.1663863.
데이터

temp_data.csv
time [UTC-OFS=+0100]: UTC+0100 시간대를 기준으로 한 시간 정보입니다.
timestamp [us]: 마이크로초 단위의 타임스탬프입니다.
hf_a0 [counts], hf_a1 [counts]: 높은 빈도 센서 데이터의 카운트입니다 (해당 센서의 세부 사항은 명시되지 않았습니다).
temp_a0 [mC], temp_a1 [mC]: 밀리도 (mC) 단위의 온도 측정값입니다.
ax, ay, az: 아마도 가속도계에서 측정된 x, y, z 축의 가속도 데이터일 것입니다.
battery_voltage [mV]: 밀리볼트(mV) 단위의 배터리 전압입니다.
cbt [mC]: 밀리도(mC) 단위의 중심체온입니다.
목표는 특정 체온을 측정했을 때의 시간을 예측하는 것이므로, temp_a0 [mC] 또는 temp_a1 [mC], 혹은 cbt [mC] 중에서 체온 데이터로 가장 적합한 열을 사용할 수 있습니다. 시간 예측에는 time [UTC-OFS=+0100] 열의 데이터를 사용할 수 있습니다.
드라이브 연동

from google.colab import drive
drive.mount('/content/drive')%tensorflow_version 2.x
import tensorflow as tf
device_name = tf.test.gpu_device_name()
if device_name != '/device:GPU:0':
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))from tensorflow.keras import Sequential
from tensorflow.keras import layers
from tensorflow.keras.optimizers import RMSprop
1.data
import keras
data_dir = './datasets/jena_climate/'
fname = os.path.join(data_dir,'jena_climate_2009_2016.csv')
f = open(fname)
data = f.read() #data에 읽어옴
f.close()
lines = data.split('\n')
header = lines[0].split(',') #헤더만 넣음
lines = lines[1:] #로우들(데이터들)
print(header)
print("데이터의 수" ,len(lines))컬럼들
['time [UTC-OFS=+0100]', 'timestamp [us]', 'hf_a0 [counts]', 'temp_a0 [mC]', 'hf_a1 [counts]', 'temp_a1 [mC]', 'ax', 'ay', 'az', 'battery_voltage [mV]', 'cbt [mC]', '', '', '', '', '', '', '', '', '', '', '', '']
데이터의 수 248930
2. 넘파이 차원형태로 만들어주기+ '정규화' + '차트분석'
(zeros로 원하는 np 차원 형태 만들어 준후 거기다 넣어주는 방식입니다.)
원하는 데이터 테이블 만들어주기
import pandas as pd
# 데이터 파일 로드
file_path = '/content/drive/MyDrive/SRC/temp_data.csv' # 실제 파일 경로로 변경해주세요
data = pd.read_csv(file_path)
# 'Unnamed' 열 제거
data = data.loc[:, ~data.columns.str.contains('^Unnamed')]
# 'time [UTC-OFS=+0100]' 열을 datetime 형식으로 변환
data['time [UTC-OFS=+0100]'] = pd.to_datetime(data['time [UTC-OFS=+0100]'])
# 'cbt [mC]'를 섭씨 온도(°C)로 변환 (밀리도 -> 도)
data['cbt [°C]'] = data['cbt [mC]'] / 1000
# 'cbt [mC]'가 0인 행 제거
data = data[data['cbt [mC]'] != 0]
# 필요한 열만 선택
cleaned_data = data[['time [UTC-OFS=+0100]', 'cbt [°C]']]
# 데이터 확인
print(cleaned_data.head())


시간을 다루는데.. 분으로 다 바꿔보자.
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.optimizers import Adam
import numpy as np
import matplotlib.pyplot as plt
# 데이터 파일 로드
file_path = '/content/drive/MyDrive/SRC/temp_data.csv' # 실제 파일 경로로 변경해주세요
data = pd.read_csv(file_path)
# 'Unnamed' 열 제거
data = data.loc[:, ~data.columns.str.contains('^Unnamed')]
# 'time [UTC-OFS=+0100]' 열을 datetime 형식으로 변환
data['time [UTC-OFS=+0100]'] = pd.to_datetime(data['time [UTC-OFS=+0100]'])
# 'cbt [mC]'를 섭씨 온도(°C)로 변환 (밀리도 -> 도) 및 0이 아닌 행만 선택
cleaned_data = data[data['cbt [mC]'] != 0]
cleaned_data['cbt [°C]'] = cleaned_data['cbt [mC]'] / 1000
# 정규화를 위한 Scaler 생성
scaler = MinMaxScaler()
cleaned_data['cbt_normalized'] = scaler.fit_transform(cleaned_data[['cbt [°C]']])
# # 시간 데이터를 시, 분, 초로 변환
# cleaned_data['hour'] = cleaned_data['time [UTC-OFS=+0100]'].dt.hour
# cleaned_data['minute'] = cleaned_data['time [UTC-OFS=+0100]'].dt.minute
# cleaned_data['second'] = cleaned_data['time [UTC-OFS=+0100]'].dt.second
# # 시간 데이터를 초 단위로 변환 (예: 전체 날짜와 시간을 초로 변환)
# cleaned_data['time_seconds'] = cleaned_data['time [UTC-OFS=+0100]'].dt.hour * 3600 + cleaned_data['time [UTC-OFS=+0100]'].dt.minute * 60 + cleaned_data['time [UTC-OFS=+0100]'].dt.second
# 시간 데이터를 분 단위로 변환
cleaned_data['time_minutes'] = cleaned_data['time [UTC-OFS=+0100]'].dt.hour * 60 + cleaned_data['time [UTC-OFS=+0100]'].dt.minute
시퀀스를 만들자. 데이터 묶음을 의미하는데
몇개씩할건가..
# 시퀀스 데이터 생성 함수
def create_sequences(data, sequence_length):
sequences = []
labels = []
for i in range(len(data) - sequence_length):
sequences.append(data.iloc[i:i+sequence_length]['cbt_normalized'].values.reshape((sequence_length, 1)))
labels.append(data.iloc[i+sequence_length]['time_minutes'])
return np.array(sequences), np.array(labels)
# 시퀀스 길이 정의 및 데이터 생성
sequence_length = 60
X, y = create_sequences(cleaned_data, sequence_length)
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
LSTM 레이어를.. 만든다고 나아질까.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from tensorflow.keras.optimizers import Adam
# 모델 구성
model = Sequential()
# 첫 번째 LSTM 층
model.add(LSTM(128, input_shape=(sequence_length, 1), return_sequences=True)) # return_sequences=True는 다음 LSTM 층을 위해 필요
model.add(Dropout(0.2)) # Dropout 층 추가
# 두 번째 LSTM 층
model.add(LSTM(64, return_sequences=False)) # 두 번째 LSTM 층은 마지막 층이므로 return_sequences=False
model.add(Dropout(0.2)) # Dropout 층 추가
# 출력 층
model.add(Dense(1))
# 모델 컴파일
optimizer = Adam(lr=0.001)
model.compile(optimizer=optimizer, loss='mse')
# 모델 요약 출력
model.summary()
# 모델 훈련
history = model.fit(X_train, y_train, epochs=20, batch_size=32, validation_split=0.1)
# 학습 과정 시각화
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='validation')
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='upper left')
plt.show()

음...
평가해볼까..
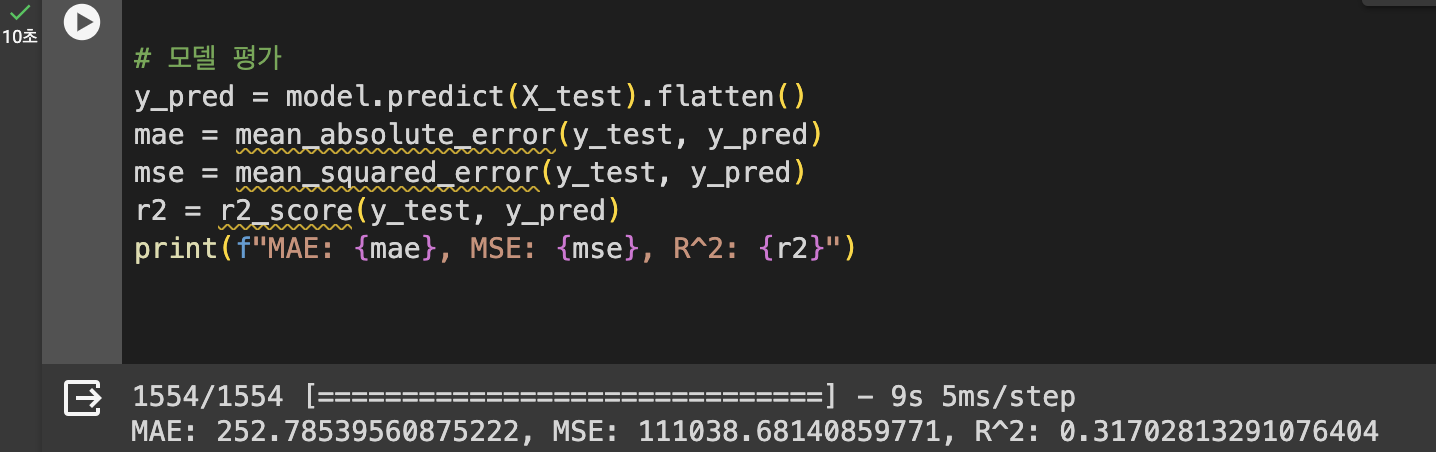
# 모델 평가
y_pred = model.predict(X_test).flatten()
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"MAE: {mae}, MSE: {mse}, R^2: {r2}")후.. 31.7 퍼센트 맞음..
+++
다음 과제
조도센서 데이터를 갖는 다면?
실내. 실외.. 밝기가 영향을 미칠듯 흠......

model_path = '/content/drive/My Drive/SRC/my_model.h5' # 'your_model_directory'는 실제 모델을 저장할 폴더명으로 변경
model.save(model_path)
모델..만들어서 TouchDesigner에서 활용해보자..
'AI > Generate img' 카테고리의 다른 글
| AI: viggle ? + comfyUI 캐릭터 움직이기 (0) | 2024.07.09 |
|---|---|
| stable diffusion _ 360 rotation _ character texture_ ComfyUI (0) | 2024.07.03 |
| Deforum-Stable-Diffusion_AE_motionBro_part2.. (0) | 2023.08.06 |
| Stable diffusion webui _ aftereffect_motion bro (plug-in) (0) | 2023.08.06 |
| Chat GPT _ PDF _ plugin (0) | 2023.06.17 |
- Total
- Today
- Yesterday
- node.js
- zclaw
- AI
- MCP
- opticalflow
- sequelize
- 라즈베리파이
- three.js
- OpenClaw
- VFXgraph
- opencv
- TouchDesigner
- ESP32
- CNC
- MQTT
- RNN
- colab
- Unity
- docker
- Midjourney
- houdini
- 유니티
- 후디니
- Arduino
- Python
- 4d guassian splatting
- DeepLeaning
- Express
- VR
- Java
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |